
Google DeepMind has released SIMA 2 to test how far generalist embodied agents can go inside complex 3D game worlds. SIMA’s (Scalable Instructable Multiworld Agent) new version upgrades the original instruction follower into a Gemini driven system that reasons about goals, explains its plans, and improves from self play in many different environments.
From SIMA 1 to SIMA 2
The first SIMA, released in 2024, learned more than 600 language following skills such as ‘turn left’, ‘climb the ladder’, and ‘open the map’. It controlled commercial games only from rendered pixels and a virtual keyboard and mouse, without any access to game internals. On complex tasks, DeepMind reported a SIMA 1 success rate of about 31 percent, while human players reached about 71 percent on the same benchmark.
SIMA 2 keeps the same embodied interface but replaces the core policy with a Gemini model. According to a TechCrunch article that the system uses Gemini 2.5 Flash Lite as the reasoning engine. This changes SIMA from a direct mapping between pixels and actions into an agent that forms an internal plan, reasons in language, and then executes the necessary action sequence in the game. DeepMind describes this as moving from an instruction follower to an interactive gaming companion that collaborates with the player.
Architecture, Gemini in the control loop
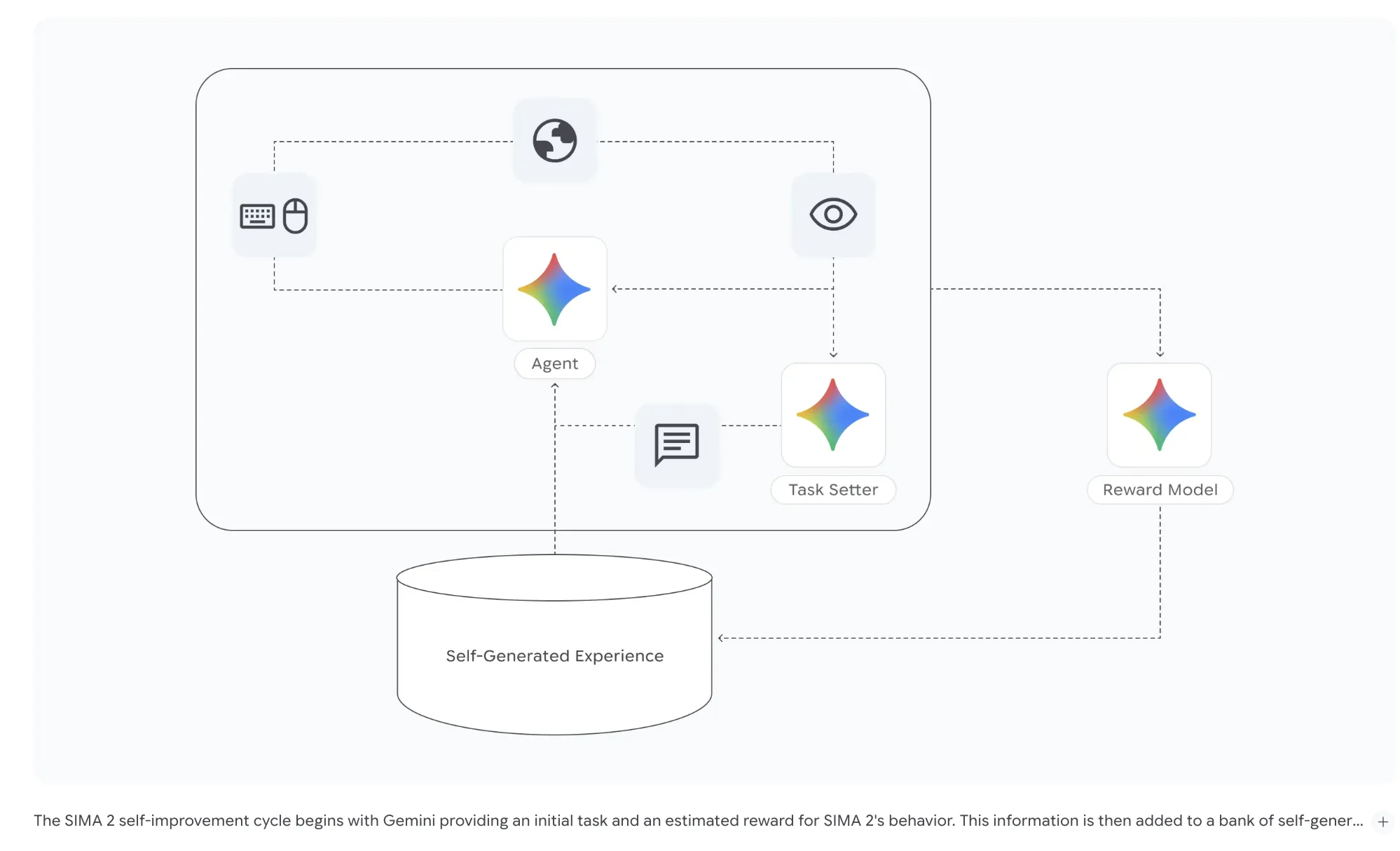
The SIMA 2 architecture integrates Gemini as the agent core. The model receives visual observations and user instructions, infers a high level goal, and produces actions that are sent through the virtual keyboard and mouse interface. Training uses a mix of human demonstration videos with language labels and labels generated by Gemini itself. This supervision lets the agent align its internal reasoning with both human intent and model generated descriptions of behavior.
Because of this training scheme, SIMA 2 can explain what it intends to do and list the steps it will take. In practice, this means the agent can answer questions about its current objective, justify its decisions, and expose an interpretable chain of thought about the environment.
Generalization and performance
The task completion plot shows SIMA 1 at about 31% and SIMA 2 at 62% that value on the main evaluation suite, with humans around the 70% range. Integrating Gemini doubles the performance of the original agent on complex tasks. The important point is not the exact number, it is the shape, the new agent closes most of the measured gap between SIMA 1 and human players on long, language specified missions in the training games.
On held out games such as ASKA and MineDojo, which are never seen during training, the DeepMind team show a similar pattern. SIMA 2 has much higher task completion than SIMA 1 in these environments, which indicates a real gain in zero shot generalization rather than overfitting to a fixed game set. The agent also transfers abstract concepts, for example it can reuse an understanding of ‘mining’ in one title when it is asked to ‘harvest’ in another.
Multimodal instructions
SIMA 2 extends the instruction channel beyond plain text. The DeepMind demonstrations show the agent following spoken commands, reacting to sketches drawn on the screen, and executing tasks from prompts that use only emojis. In one example, the user asks SIMA 2 to go to ‘the house that is the color of a ripe tomato’. The Gemini core reasons that ripe tomatoes are red, then selects and walks to the red house.
Gemini also enables instruction following in multiple natural languages and supports mixed prompts where language and visual cues are combined. For physical AI, robotics devs, this is a concrete multimodal stack, a shared representation links text, audio, images, and in game actions, and the agent uses this representation to ground abstract symbols in concrete control sequences.
Self improvement at scale
One of the main research contributions in SIMA 2 is the explicit self improvement loop. After an initial phase that uses human gameplay as a baseline, the team moves the agent into new games and lets it learn only from its own experience. A separate Gemini model generates new tasks for the agent in each world, and a reward model scores each attempt.
These trajectories are stored in a bank of self generated data. Later generations of SIMA 2 use this data during training, which allows the agent to succeed on tasks where earlier generations failed, without any fresh human demonstrations. This is a concrete example of a multitask, model in the loop data engine, where a language model specifies goals and gives feedback, and the agent converts that feedback into new competent policies.
Genie 3 worlds
To push generalization further, DeepMind combines SIMA 2 with Genie 3, a world model that generates interactive 3D environments from a single image or text prompt. In these virtual worlds, the agent has to orient itself, parse instructions, and act toward goals even though the geometry and assets differ from all training games.
The reported behavior is that SIMA 2 can navigate these Genie 3 scenes, identify objects such as benches and trees, and perform requested actions in a coherent way. This is important for researchers, it shows that a single agent can operate across commercial titles and generated environments, using the same reasoning core and control interface.
Key Takeaways
- Gemini centered architecture: SIMA 2 integrates Gemini, reported as Gemini 2.5 Flash Lite, as the core reasoning and planning module, wrapped by a visuomotor control stack that acts from pixels through a virtual keyboard and mouse across many commercial games.
- Measured performance jump over SIMA 1: On DeepMind’s main task suite, SIMA 2 roughly doubles SIMA 1’s 31 percent task completion rate and approaches human level performance in training games, while also delivering significantly higher success rates on held out environments such as ASKA and MineDojo.
- Multimodal, compositional instruction following: The agent can follow long, compositional instructions and supports multimodal prompts, including speech, sketches, and emojis, by grounding language and symbols in a shared representation over visual observations and in game actions.
- Self improvement via model generated tasks and rewards: SIMA 2 uses a Gemini based teacher to generate tasks and a learned reward model to score trajectories, building a growing experience bank that allows later generations of the agent to outperform earlier ones without additional human demonstrations.
- Stress testing with Genie 3 and implications for robotics: Coupling SIMA 2 with Genie 3, which synthesizes interactive 3D environments from images or text, shows that the agent can transfer skills to newly generated worlds, supporting DeepMind’s claim that this stack is a concrete step toward general purpose embodied agents and, eventually, more capable real world robots.
SIMA 2 is a meaningful systems milestone rather than a simple benchmark win. By embedding a trimmed Gemini 2.5 Flash lite model at the core, DeepMind team demonstrates a practical recipe that joins multimodal perception, language based planning, and a Gemini orchestrated self improving loop, validated both in commercial games and Genie 3 generated environments. Overall, SIMA 2 shows how an embodied Gemini stack can act as a realistic precursor for general purpose robotic agents.
Check out the Technical details. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.

